LiveChat
LiveChat  Support
Support 
Load Balancing: The Complete Guide to Distributing Traffic and Surviving Server Failure
A single server is a single point of failure, and a single point of failure is a bet that nothing will ever go wrong. Eventually something does — a process crashes, a disk fills, a deploy goes sideways, a traffic spike exhausts the memory — and when it happens to a one-server site, the site is simply down until a human notices and intervenes. Load balancing is the discipline that removes that bet. It places a traffic director in front of two or more servers, spreads incoming requests across them, and quietly steers users away from any server that stops answering.
This guide is the map for that whole subject. It explains what a load balancer is, how it actually routes a request, the algorithms it uses to decide where each request goes, the difference between balancing at Layer 4 and Layer 7, the choice between hardware and software balancers, and the harder problems — health checks, failover, and the stateful-application headache of sticky sessions. Each major piece links to a deeper article or a related pillar; this page connects them so you can reason about the whole system instead of memorizing isolated tricks.
Key Takeaways
• Load balancing distributes incoming traffic across multiple backend servers so no single machine carries the whole load, and so no single machine is a fatal point of failure.
• A load balancer sits in front of your servers and routes each request using an algorithm — round robin, least connections, or IP hash being the common three.
• Layer 4 balancing routes on IP and port (fast, dumb); Layer 7 routes on HTTP content like URLs and headers (slower, smarter) — most modern web setups want Layer 7.
• Health checks are what make a balancer worth having: it constantly probes each server, and the moment one fails, it stops sending traffic there — so a server can die and visitors never notice.
• Load balancing is sold as a scaling tool, but for most serious sites its more important job is availability — eliminating the single point of failure that takes down one-server setups.
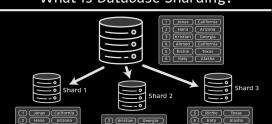
What is load balancing?
Load balancing is the practice of distributing incoming network traffic across a pool of backend servers rather than sending it all to one. Instead of `yoursite.com` pointing at a single machine, it points at a load balancer — a piece of software or hardware whose only job is to receive every request and hand it off to one of several identical servers behind it. To the visitor, nothing looks different; they see one website at one address. Behind that address, the work is being shared.
The mechanism solves two problems at once, and it is worth separating them because they are often blurred together. The first is capacity: one server can only handle so many simultaneous requests before it runs out of CPU, memory, or connections, and a balancer lets you add more servers to share the load. The second is resilience: with several servers sharing that load, the failure of any one no longer means the site goes dark — the balancer simply routes around the dead machine. Everything else in this guide exists to make those two outcomes reliable.
Why do you need to load balance traffic?
There are two motivations for putting a load balancer in front of your application, and understanding both is the difference between treating load balancing as an optional performance tweak and treating it as core architecture.
The first motivation is scaling beyond a single server. Every machine has a ceiling. You can give a server more CPU and RAM — vertical scaling — but that ceiling is finite and expensive, and at some point one box physically cannot serve your peak traffic. Load balancing enables horizontal scaling: adding more servers and spreading the work across them. Two servers handle roughly twice the traffic of one; ten handle roughly ten times. This is how large sites grow without hitting a hard wall.
The second motivation — and the one most people underweight — is high availability. A single server is, by definition, a single point of failure. When it goes down for any reason, your entire site goes down with it, and it stays down until someone diagnoses and fixes the problem. With two or more servers behind a balancer running health checks, the failure of one server is a non-event: the balancer stops routing to it and the remaining servers absorb the traffic. The site stays up. This is the property that protects revenue and reputation, and it is the reason load balancing belongs in any architecture where downtime has a real cost. The broader discipline of keeping infrastructure available is covered in our networking and reliability material.
How do load balancers actually work?
A load balancer is, at its core, a reverse proxy with a decision engine. It sits between the public internet and your pool of backend servers, and the flow of a single request runs like this: a visitor’s browser sends a request to your domain, which resolves to the balancer’s address. The balancer receives that request, applies an algorithm to choose which backend server should handle it, forwards the request to that server, waits for the response, and relays the response back to the visitor. The visitor never learns which server actually did the work, and never talks to a backend server directly.
Two ongoing background activities make this safe. The first is health checking: the balancer continuously probes each backend server — often by requesting a specific URL or opening a TCP connection — and tracks which servers are responding correctly. A server that fails its health check is marked unhealthy and pulled from rotation. The second is connection tracking, which lets the balancer know how busy each server currently is, information that smarter algorithms use to route better.
The result is a layer of indirection that buys real flexibility. Because traffic flows through the balancer, you can add servers, remove servers, take one offline for maintenance, or lose one to a crash — all without changing the address your visitors use and, ideally, without any visitor noticing. The next sections look at how the balancer decides where each request goes.
What load balancing algorithms are there?
The algorithm is the rule the balancer uses to pick a backend server for each incoming request. The choice matters because different algorithms suit different workloads, and the wrong one can pile traffic onto a server that is already struggling while another sits idle. The three most common algorithms cover the large majority of real-world needs.
| Algorithm | How it decides | Best for | Trade-off |
|---|---|---|---|
| Round robin | Sends each request to the next server in sequence, cycling through the pool | Servers of equal capacity handling short, uniform requests | Ignores how busy each server actually is — a slow request can leave one server overloaded |
| Least connections | Sends each request to the server with the fewest active connections | Requests of uneven duration, long-lived connections | Slightly more overhead to track connection counts; usually worth it |
| IP hash | Hashes the visitor’s IP to always route them to the same server | Stateful apps that need a visitor pinned to one server | Uneven distribution if some IPs (or proxies) carry far more traffic than others |
Round robin is the simplest and the default in many setups: it just rotates through the servers in order, which works beautifully when every server is identical and every request takes roughly the same amount of work. Least connections is smarter for real traffic, where some requests finish in milliseconds and others hold a connection open for seconds — it steers new requests toward the server currently doing the least, which keeps load even. IP hash is the odd one out: it deliberately sends a given visitor to the same server every time, which is one way to solve the sticky-session problem we cover further down. Most setups also support weighted variants, where a more powerful server is given a larger share of traffic. How to configure these in practice is covered in our HAProxy and Nginx guides.
What is the difference between Layer 4 and Layer 7 load balancing?
Load balancers operate at one of two levels of the network stack, and the distinction shapes what the balancer can see and therefore what decisions it can make. The names come from the OSI model: Layer 4 is the transport layer (TCP/UDP), and Layer 7 is the application layer (HTTP). The deeper concepts behind these layers live in our networking pillar.
| Aspect | Layer 4 (transport) | Layer 7 (application) |
|---|---|---|
| Routes based on | IP address and port | URL path, hostname, headers, cookies, request content |
| Sees the content? | No — moves packets without inspecting them | Yes — reads and understands the HTTP request |
| Speed | Faster, lower overhead | Slower, more processing per request |
| Capabilities | Simple, fast forwarding | Path-based routing, SSL termination, header inspection, sticky sessions by cookie |
| Typical use | Raw throughput, non-HTTP protocols | Modern web apps, microservices, content-aware routing |
A Layer 4 balancer is fast and indifferent: it forwards packets based on IP and port without ever looking inside them. It does not know or care whether the traffic is a web page, an API call, or a database connection. That ignorance makes it efficient and protocol-agnostic, which is exactly what you want for raw throughput or non-HTTP traffic.
A Layer 7 balancer reads the actual HTTP request, and that visibility unlocks far smarter routing. It can send `/api/` requests to one pool of servers and `/images/` to another, route by hostname for multiple sites, terminate SSL so the backends do not have to, inspect headers, and implement cookie-based sticky sessions. The cost is more processing per request. For most modern web applications, the intelligence of Layer 7 is worth the overhead, and it is what tools like Nginx and HAProxy give you out of the box.
Hardware or software load balancers — which should you use?
Load balancers come in two broad forms, and for almost everyone reading this, the answer is software — but it helps to know why the other category exists.
Hardware load balancers are dedicated physical appliances built and sold by network vendors. They are purpose-built devices that sit in a data center rack and handle balancing in specialized silicon, which makes them extremely fast and capable of enormous throughput. The downsides are cost and rigidity: they are expensive to buy, expensive to scale, and tied to physical infrastructure. They make sense for very large enterprises with extreme throughput requirements and the budget to match.
Software load balancers run as ordinary programs on standard servers, and they are what the overwhelming majority of modern infrastructure uses. The two most common are HAProxy — a dedicated, high-performance balancer that excels at both Layer 4 and Layer 7 — and Nginx, a web server that doubles as a capable reverse proxy and load balancer. Both are free, battle-tested, and flexible enough to run anywhere you can run a Linux server. Cloud providers also offer managed load balancers as a service: you click a button and the provider runs the balancing layer for you, scaling it automatically, which trades some control for convenience. Running your own software balancer on a VPS or dedicated server gives you maximum control; the managed option in a cloud environment gives you less to administer. The trade-offs between self-managed and managed infrastructure are explored in our cloud and dedicated hosting pillars.
How do health checks and failover keep a site online?
This is the part of load balancing that earns its keep, and it deserves more attention than the algorithms usually get. A health check is a probe the balancer sends to each backend server on a regular interval to confirm the server is alive and responding correctly. The check can be as simple as opening a TCP connection, or as meaningful as requesting a specific URL — a `/health` endpoint, for example — and confirming it returns a successful response. As long as a server passes its checks, it stays in rotation. The moment it fails a defined number of consecutive checks, the balancer marks it unhealthy and stops sending it traffic.
Here is the insight that should reframe how you think about load balancing: it is almost always sold as a scaling tool — “handle more traffic” — but for most serious sites, its more important job is availability. Consider what a one-server setup actually is: a single machine that, the instant it crashes at 3am, takes your entire site offline until a human wakes up, diagnoses the problem, and fixes it — minutes or hours of downtime, every visitor seeing an error, during the exact window when nobody is watching. Now put two servers behind a balancer doing health checks. One server dies at 3am. The balancer notices within seconds, pulls it from rotation, and routes every request to the survivor. Visitors notice nothing. No page goes down, no revenue is lost, no reputation is dented, and the on-call engineer can fix the dead box in the morning over coffee instead of in a panic at night. The single point of failure — the thing that makes a one-server site fundamentally fragile — simply ceases to exist. So the real question to ask of your architecture is not only “can I handle more traffic,” but “can my site survive a server failing at 3am with nobody watching.” Load balancing answers both, and the second answer is the one that protects revenue and reputation. The scaling is the headline; the availability is the substance.
Failover is the name for this automatic rerouting around failure. Done well, it is invisible: a backend can crash, get rebooted, or be pulled for a deploy, and traffic flows uninterrupted to the healthy servers. For this to work cleanly you need genuine redundancy — at least two servers that can each serve the full application — and you need the balancer itself to not become a new single point of failure, which is why production setups often run the balancer in a redundant pair too. Designing this redundancy properly is a security-and-reliability concern as much as a performance one.
What are sticky sessions and why do they cause trouble?
Load balancing is simple when your servers are stateless — when any server can handle any request because none of them stores information that the others lack. The trouble begins when your application is stateful: when a server remembers something about a visitor, like a login session held in that server’s local memory, and the next request from that visitor must reach the *same* server or the session is lost.
A round-robin balancer, blind to this, will happily send a logged-in visitor’s next request to a different server that has no record of their session — and the visitor gets logged out. Sticky sessions (also called session persistence or session affinity) are the workaround: the balancer pins each visitor to one specific backend server for the duration of their session, usually by setting a cookie or by hashing their IP address. Once pinned, every request from that visitor goes to the same server, and the in-memory session stays intact.
Sticky sessions work, but they are best understood as a patch over an architectural weakness, and it is worth naming the trade-offs. Pinning visitors undermines even load distribution, because traffic follows sessions rather than current server load. Worse, it reintroduces a failure mode load balancing was supposed to remove: if the server a visitor is stuck to dies, that visitor’s session dies with it. The cleaner long-term fix is to make the application stateless by moving session state into a shared store — a database or an in-memory cache that every server can read — so any server can serve any request and stickiness becomes unnecessary. How to externalize session state into a shared store is covered in our databases pillar.
How does load balancing work with databases and scaling?
Load balancing the web tier is only half the picture, because behind those web servers usually sits a database, and a database has its own scaling and availability challenges. The same principle — spread the work, remove the single point of failure — applies, but databases complicate it because they hold state that must stay consistent.
The common pattern is read replicas. Most applications read from the database far more often than they write to it, so you keep one primary database that handles all writes and replicate its data to one or more read-only copies. Read queries are then balanced across the replicas, spreading the heaviest part of the database load, while writes funnel to the single primary. This is load balancing applied to data: the read traffic is distributed, and losing a replica is survivable because the others still serve reads.
The reason databases need this special handling — and cannot simply be balanced like stateless web servers — is that every copy must agree on the data. A write to one replica that does not propagate to the others produces inconsistency, which is why the primary-replica model exists in the first place. The mechanics of replication, read scaling, and keeping data consistent across copies are the subject of our databases pillar.
When do you actually need load balancing?
Load balancing is not free — it adds servers, configuration, and operational complexity — so it is worth being clear about when the benefit justifies the cost rather than reaching for it reflexively.
You need load balancing when one or more of these is true: your traffic exceeds what a single server can comfortably handle, and adding capacity means adding servers rather than just enlarging one; you have an uptime requirement — a service-level agreement, a revenue-critical store, or simply a reputation that downtime would damage — that a single point of failure makes untenable; or you are running an application where failed deploys or maintenance must not take the site offline, because a balancer lets you update servers one at a time behind it. Conversely, a small site with modest, steady traffic and a tolerant audience may be perfectly well served by a single, well-provisioned server with good backups; introducing a balancer there adds complexity without proportionate benefit.
The honest signal is usually the cost of an outage. If an hour of downtime costs you real money or real trust, the single-server gamble is one you should stop taking, and load balancing across at least two servers is the architecture that ends it. The infrastructure to run that — multiple servers with root control and strong networking — is what dedicated and cloud hosting provide.
How is load balancing different from a CDN or vertical scaling?
Load balancing is often confused with two adjacent techniques — vertical scaling and a CDN — because all three are ways to make a site faster or more capable. They solve different problems, and the clearest way to think about it is that they combine rather than compete.
Vertical scaling means making one server bigger: more CPU, more RAM, faster storage. It is the simplest way to handle more load and needs no architectural change, but it has a hard ceiling — there is a largest server you can buy — and it does nothing for availability, because one bigger server is still a single point of failure. Load balancing (horizontal scaling) instead adds more servers and spreads work across them, which has no practical ceiling and removes the single point of failure. The usual progression is to scale up vertically until it gets expensive, then scale out horizontally with a balancer.
A CDN solves a different problem: distance. A content delivery network caches your static files — images, scripts, stylesheets — at edge locations near your visitors, cutting the latency of delivering those assets across the globe. It does not balance the dynamic requests that hit your origin, and it gives you no failover for your application logic. Load balancing distributes the *dynamic* work across origin servers; a CDN distributes the *static* assets geographically. Serious sites use both: a CDN for fast static delivery worldwide, and a balancer to keep the origin scalable and available.
The building blocks for a load-balanced, highly available setup — DarazHost
Every architecture in this guide rests on the same foundation: multiple real servers, strong networking between them, and the root-level control to configure the balancing layer exactly how your application needs it. That is precisely what DarazHost provides. Its VPS and dedicated infrastructure gives you the building blocks for high availability — several independent servers rather than one fragile box, a strong network to connect them, and full root access to deploy HAProxy or Nginx as your balancer and stand up database replicas behind it.
For mission-critical sites that genuinely cannot afford downtime, that combination is what turns “we should be more resilient” into a working, failover-capable system. With engineering-grade infrastructure and 24/7 support from people who can help you architect it — from the balancer in front to the replicas behind — DarazHost gives you the components to build a setup where a single server failing at 3am is a non-event your visitors never see.
Frequently asked questions
What is load balancing in simple terms? Load balancing is putting a traffic director in front of several identical servers so that incoming requests are spread across all of them instead of overwhelming one. To visitors it looks like a single website at a single address, but behind that address the work is shared, and if any one server fails, the balancer routes around it so the site stays up.
Does load balancing require more than one server? Yes — that is the whole point. A load balancer distributes traffic across a pool of backend servers, so you need at least two for it to mean anything. With a single server there is nothing to balance and no redundancy, which leaves you with the single point of failure that load balancing exists to remove.
What is the difference between Layer 4 and Layer 7 load balancing? A Layer 4 balancer routes traffic based only on IP address and port without looking inside the request, which makes it very fast but unable to make content-aware decisions. A Layer 7 balancer reads the actual HTTP request — the URL, headers, and cookies — so it can route by path, terminate SSL, and run cookie-based sticky sessions, at the cost of more processing per request. Most modern web applications want Layer 7.
What is the best load balancing algorithm? There is no single best algorithm; the right one depends on your traffic. Round robin works well when all servers and requests are similar. Least connections is usually better for real-world traffic where request durations vary, because it routes to the least-busy server. IP hash is used when you need a visitor pinned to the same server. Many setups also weight servers by capacity.
Do I still need sticky sessions if I use load balancing? Only if your application stores session state in a server’s local memory. If it does, sticky sessions pin each visitor to one server so their session survives. The cleaner approach is to make the application stateless by moving session data into a shared store every server can read, which removes the need for stickiness and avoids losing sessions when a server fails.
Is load balancing about handling more traffic or staying online? Both, but the availability benefit is the one most people underrate. Yes, a balancer lets you add servers to handle more traffic. But its more valuable job for most sites is eliminating the single point of failure: with health checks running across two or more servers, any one server can crash and the balancer reroutes traffic instantly, so visitors never see an outage. The scaling is the headline; the always-on resilience is the substance.